For Facebook, it’s a quick Google search away; you can download a copy through your general account settings. All things considered, it’s a pretty huge wealth of data. Imagine just your messages alone—a rightly massive wall of text containing countless interesting insights about you and the people you talk to. The only catch is you have to be curious enough to sort through it all.
The “obvious” way to analyze text message data is to find out the words you used the most often, and that sounded good enough to me. If you’d like to read about how I actually did the analysis or want to do it for your own Facebook messages, you can check out a download of the script and an explanation of it here (Yikes! It’s still under construction).
Otherwise, let’s take an in-depth look at how I talk to people on Facebook.
Three Hundred Twenty-three Thousand Nine Hundred Forty-seven
—the total number of words I’ve sent through Facebook Messenger since I joined, ignoring punctuation (which has the effect of counting contracted words as one), numbers, emoticons, and generally anything that isn’t an English letter. It’s a pretty stupefying number.
And of course, we’re going to do the old back-of-the-napkin time conversion. The average English word is about 5 letters long, and the average person types English at around 200 letters per minute. These are both pretty dubious estimates since:
a) The average word I’ve sent in a text is probably shorter than the average English word.
b) I’ve sent the majority of my Facebook messages through my phone, which means I also probably typed slower than the average keyboard typing speed.
I’m hoping the errors will sort of cancel out, though, since they work against each other in theory. Anyways, 323947 words times 5 letters per word divided by 200 letters per minute works out to:
8099 minutes or just about 135 hours.
That’s 5.6 days of my life spent just typing Facebook messages. It’s at least a little embarrassing—putting that figure out there.
And remember, that quantity doesn’t even account for the fact that:
- Any messages where I sent only an image or an emoji or a sticker (hey, those were popular at one point) doesn’t contribute at all to the final word count.
- I’ve probably spent a good additional portion of that time just thinking about what to send.
- I’ve deleted a number of conversations with people that I’ve probably written a huge number of messages to.
Before taking a look at my word frequency though, here are some other fun stats:
I’ve sent (at least) 83874 messages with text over the course of 7 years and 10 days, with an average of 3.6 words per text message (excluding outliers–there were enough to make a difference) and 32.7 messages per day. Using the above estimate of 135 total hours, I’ve spent about 0.2% of all my time since I joined Facebook typing messages on their service (Yowza!).
I’ve sent 22848 messages to my “most talked to” person, which accounts for just about 27% of all my sent messages.
Word Frequency
So, which words did I use the most often?
Just so you know, before I did the analysis, I removed any “stop words” (i.e. common, uninteresting words like “but,” “the” or “and”).
With those out of the way so we can see my own unique word habits, here are my 50 most used words and their usage amounts in order of frequency:
['u' '2481'] ['think' '1472'] ['oh' '1323'] ['know' '940'] ['shit' '834'] ['ill' '823'] ['time' '823'] ['fuck' '811'] ['lmao' '808'] ['idk' '784'] ['want' '780'] ['probably' '771'] ['actually' '750'] ['lol' '745'] ['ur' '667'] ['w' '657'] ['kinda' '632'] ['going' '609'] ['thing' '604'] ['bc' '596'] ['nice' '595'] ['thanks' '576'] ['haha' '555'] ['rip' '552'] ['rly' '547'] ['dude' '545'] ['bad' '542'] ['hey' '538'] ['need' '532'] ['tho' '525'] ['people' '524'] ['yes' '509'] ['feel' '505'] ['make' '504'] ['wow' '491'] ['didnt' '483'] ['youre' '477'] ['lot' '472'] ['pretty' '470'] ['better' '459'] ['guess' '445'] ['wait' '437'] ['day' '432'] ['today' '428'] ['maybe' '414'] ['tomorrow' '403'] ['things' '403'] ['theres' '403'] ['man' '399'] ['fun' '390']
So here’s what I’ve first noticed from this list, but tell me if you find anything else interesting:
“U” is my most common word, and the way I use it isn’t even valid English. Actually, “you” was in the list of stopwords I removed, but I wanted to keep abbreviations and other quirks since they help define my own personal texting patterns.
I use “think” a lot more than “know,” so maybe I make more claims in messages that I can’t back up. It’s possible a “think-to-know ratio” could be a decent word statistic to measure someone’s confidence in their ideas.
Two profanities (“shit” and “fuck”—classy) made it to my top ten, which should make sense to us; they aren’t in any list of stop words and, all things considered, they’re pretty versatile words.
Ten out of fifty (20%) of my top words are abbreviations (“u,” “idk,” “lmao”). I don’t know how that compares to the texting average, but it seems fairly reasonable.
…
Do my top words change based on the people I’m talking to? Well, you be the judge.
Here’s the list of my top words to a longtime good friend of mine:
['u' '189'] ['haha' '135'] ['shit' '120'] ['think' '79'] ['kinda' '74'] ['idk' '67'] ['oh' '65'] ['dude' '59'] ['fuck' '58'] ['probably' '58'] ['rly' '52'] ['alright' '45'] ['lmao' '45'] ['ur' '44'] ['know' '39'] ['time' '38'] ['want' '33'] ['whats' '33'] ['didnt' '32'] ['ill' '31'] ['way' '30'] ['w' '29'] ['rn' '29'] ['feel' '28'] ['theres' '26'] ['thing' '26'] ['things' '26'] ['thought' '25'] ['bc' '25'] ['man' '24'] ['wait' '24'] ['high' '23'] ['maybe' '23'] ['need' '23'] ['actually' '23'] ['lot' '23'] ['p' '22'] ['guess' '21'] ['nice' '21'] ['huh' '21'] ['said' '21'] ['holy' '20'] ['n' '20'] ['say' '20'] ['tho' '20'] ['read' '19'] ['mean' '19'] ['make' '19'] ['abt' '19'] ['better' '19']
Compare it to the list of my top words to an acquaintance, who I’ve talked to just a few times in real life.
['u' '55'] ['shit' '30'] ['w' '22'] ['hi' '21'] ['actually' '20'] ['idk' '19'] ['probably' '19'] ['math' '18'] ['hey' '18'] ['thanks' '18'] ['want' '18'] ['ill' '17'] ['home' '16'] ['know' '16'] ['bc' '16'] ['time' '16'] ['wow' '16'] ['fuck' '15'] ['oh' '14'] ['think' '14'] ['balm' '14'] ['yep' '13'] ['hello' '13'] ['tho' '13'] ['ur' '13'] ['class' '12'] ['rip' '12'] ['yes' '11'] ['theres' '11'] ['lol' '11'] ['tomorrow' '11'] ['need' '11'] ['doing' '10'] ['thing' '10'] ['p' '10'] ['phys' '10'] ['lmao' '10'] ['kinda' '10'] ['lot' '10'] ['nice' '10'] ['wait' '9'] ['didnt' '9'] ['maybe' '9'] ['fine' '9'] ['k' '8'] ['mm' '8'] ['stop' '8'] ['check' '8'] ['rn' '8'] ['work' '7']
Also, the words I’ve sent the most to all guys compared to girls…
Guys:
['u' '858'] ['oh' '488'] ['think' '462'] ['lol' '403'] ['fuck' '389'] ['know' '352'] ['actually' '340'] ['wow' '322'] ['ill' '313'] ['ur' '286'] ['time' '279'] ['want' '267'] ['going' '256'] ['shit' '251'] ['idk' '239'] ['hey' '238'] ['thing' '234'] ['probably' '233'] ['wait' '232'] ['people' '220'] ['need' '203'] ['wtf' '200'] ['make' '199'] ['pretty' '199'] ['tho' '193'] ['kinda' '181'] ['guess' '178'] ['w' '176'] ['rip' '176'] ['yes' '174'] ['didnt' '169'] ['bad' '169'] ['thanks' '165'] ['better' '163'] ['theres' '162'] ['hes' '158'] ['lmao' '157'] ['dude' '156'] ['said' '155'] ['omg' '154'] ['tomorrow' '148'] ['youre' '147'] ['lot' '145'] ['mean' '145'] ['game' '145'] ['look' '142'] ['p' '141'] ['maybe' '140'] ['nice' '139'] ['say' '135'] ['math' '133']
Girls:
['u' '1653'] ['think' '1020'] ['oh' '841'] ['lmao' '684'] ['know' '594'] ['shit' '586'] ['idk' '549'] ['time' '548'] ['probably' '544'] ['want' '513'] ['ill' '511'] ['bc' '498'] ['w' '497'] ['nice' '456'] ['kinda' '454'] ['rly' '448'] ['haha' '441'] ['fuck' '428'] ['actually' '419'] ['thanks' '418'] ['feel' '409'] ['dude' '389'] ['rip' '387'] ['ur' '384'] ['thing' '379'] ['bad' '377'] ['going' '355'] ['lol' '349'] ['yes' '336'] ['tho' '334'] ['youre' '332'] ['need' '331'] ['abt' '330'] ['lot' '330'] ['day' '324'] ['today' '322'] ['didnt' '320'] ['things' '315'] ['make' '312'] ['people' '307'] ['better' '305'] ['hey' '301'] ['fun' '289'] ['yep' '288'] ['b' '282'] ['pretty' '275'] ['man' '274'] ['maybe' '274'] ['alright' '271'] ['ppl' '270'] ['guess' '270']
There’s not too many differences, but I did notice that “thanks” is ranked a lot higher for girls than guys.
Also, “today” is in the top 50 for girls but not guys, whereas “tomorrow” has the opposite case. Bros before hoes? Not for me, I guess.
Zipf’s Law
One really interesting phenomena is that, taken as a whole, the total distribution of my word counts (i.e. including stop words) in order of frequency appears to closely follow a trend according to something called Zipf’s law.
The quick rundown is that Zipf’s law is a quirk of probability distributions first formalized by George Kingsley Zipf, who found that a lot of data sets in the physical and social sciences can be approximated by just one distribution—called a Zipfian.
An easy way to describe a Zipfian distribution is that it’s logarithmic (i.e. if you plot it on a log-log scale, it’ll look linear). Zipf’s law thus predicts that, given some long-form text written in a natural language, the frequency of words used will be inversely proportional to its rank (i.e. 1st is twice as common as 2nd, and three times as common as 3rd, etc.).
In our case, the data set of my most used words can be considered a social science data set, and it’s astonishing how close it follows the distribution. Take a look for yourself:

vs.

Interestingly enough, Wikipedia also published a graph of their own word frequencies, taken from a data set of 10,000,000 words randomly chosen from their own archives; they’ve noticed it also closely follows a Zipfian, enough to include the graph on their article about Zipf’s law. How meta!

vs.

So, how about that? Some guy who was alive a century ago predicted how often I use words in text messages.
Over the course of some 7 years of texting, I’ve managed to produce a data set that matches Zipf’s prediction. I think that’s really something special.
What other interesting things can you find in text message analysis (either from looking at trends in my data set or your own)? I’m sure there are insights I’ve missed, and interesting comparisons I didn’t try.
There’s also so much more to review than just word frequency like I did here. Have at it, and tell me how it goes.














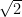 ), and so on. The sum would then be
), and so on. The sum would then be 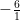 (the 6 nearest neighbors at distance 1) +
(the 6 nearest neighbors at distance 1) + 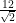 (there are 12 next-closest atoms distance
(there are 12 next-closest atoms distance  (the 8 “corners” of the first 3x3x3) +
(the 8 “corners” of the first 3x3x3) + 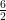 (similar to the nearest neighbors but one out) and so on.
(similar to the nearest neighbors but one out) and so on.

