I finished finals today, and I’m pretty glad; it’s been a long, grueling spring semester and summer should prove one hell of a reward this time around.
After submitting my last assignment of the 2016-2017 school year, a finicky problem set for a thermodynamics course, I walked to my bus stop past a tree boasting a great deal of flowering buds—not uncommon for the season. And as I strolled by, its petals floated down and were carried by the wind, which made for a pleasant scene.
So I moved in to get a closer look and to take a picture of it. Here it is.

I also ended up noticing that they landed in a very particular pattern on the ground. Basically, as you got closer to the tree, there were more petals.
And that makes sense: wind can only carry the petals so far from where they start on their branches. But there were so many petals that have been falling for so long that, as a whole, they formed a remarkably clear map of their falling distribution.
Incredibly, you could easily make out something that resembled a sort of gradient towards the center, kind of like the charge distribution of a point charge in 2D: heavy in the middle, and lighter as you get further out.
But it wasn’t this pattern the entire way through: nearing the center of the tree, the petal density only got higher up to a point, after which it started decreasing again. This also makes sense because, well, tree trunks don’t grow petals.
But it was undeniable that the pattern had a nice unique beauty to it, and so I wanted to see if I could remake it myself. I also figured that simulating the random falling of petals to get a sense of the end distribution was similar to a Monte Carlo method, which uses random sampling to solve problems in statistics.
It ended up looking pretty awesome, and it was actually a relatively simple and short method. Here’s what I did:
Part Zero: The Game Plan
“Monte Carlo Petals” should consist of three main steps. First, we have to set the petal starting positions. Then, we need an algorithm to generate a random wind vector for each petal. Finally, we add each wind vector to the starting position and plot the results.
Let’s get this big one out of the way first: how do we generate random vector directions? If you think about it, that’s basically the backbone of this whole project. We need some way to make a set of equal-length (preferably unit-length) vectors that are distributed randomly with respect to direction. After that, we can scale the magnitudes using any probability distribution we like.
I found this online for Python, which seems to do the trick:
import numpy as np
def random_vec(dims, number):
vecs = np.random.normal(size = (number,dims))
mags = np.linalg.norm(vecs, axis=-1)
return(vecs/mags[...,np.newaxis])
It seems fairly robust, too. Plotting:
import matplotlib.pyplot as plt
from matplotlib import collections
def main():
ends = random_vec(2,1000)
vectors = np.insert(ends[:,np.newaxis], 0, 0, axis=1)
figure,axis = plt.subplots()
axis.add_collection(collections.LineCollection(vectors))
axis.axis((-1,1,-1,1))
plt.show()
main()
x = random_vec(2,200)
plt.scatter(x[:,0],x[:,1])
plt.show()
We get this graph:

So, we’ll just use that code. Why not? A little help can speed things up tremendously.
Part One: Petal Ring
My model of petal starting positions was pretty basic; I just created a randomly distributed ring of them, modeling how the trunk and inner branches wouldn’t carry petals.
Take a random direction vector of length one and multiply it by some random value in between a larger number and a smaller number. Do this enough times, and you’ll map out a ring. The inner radius of your ring is the smaller number, and the outer radius is the larger one.
Using our random_vec() function:
Niter = 2000
startvecs = np.array(random_vec(2,Niter))
mags = np.random.uniform(low = 12, high = 15, size = Niter)
for i in range(Niter):
startvecs[i] = startvecs[i]*mags[i]
plt.scatter(startvecs[:,0],startvecs[:,1])
plt.show()

Basically, we made 2000 “petals” in a ring with inner radius 12 and outer radius 15. It’s worth it to note that the outermost part of the ring has a lower density than the innermost, since there’s slightly more space to fill out there with essentially the same chance of a petal landing in any given place.
Part Two: Some Wind Vectors
How strong is wind, on average? Its gotta be more than zero, if there’s any wind at all. The wind blowing near the tree when I first saw it was pretty strong, but not overwhelming.
How each petal is directionally affected by wind should be pretty random as well (even if the wind itself is quite biased, it’ll change over time). We’ll start with the same random_vec() function usage as last time to make 2000 random directions. Then, we’ll multiply each direction by a length determined by a normal distribution around some set average.
This should make for a better wind model than, say, a uniform distribution, like we used for the petal ring. A normal distribution lets us make most of the wind around a set average strength, with less likely deviations from that average.
Here’s what it looks like written down:
avgwind = 5.0
winddev = 3.0
windvecs = np.array(random_vec(2,Niter))
windmags = np.random.normal(loc=avgwind,scale=winddev,size=Niter)
for i in range(Niter):
windvecs[i] = windvecs[i]*[windmags[i]]
plt.scatter(windvecs[:,0],windvecs[:,1])
plt.show()
And the resulting graph:

You’ll notice that our average wind is low enough so that there’s still a lot of distribution around the center, especially since negative wind strength will just reverse the vector. This is intentional. We want a good portion of the petals to not move a lot, so that our final plot recognizes the starting positions well. Still, we want a lot of petals to move some too, which is why we set our average above 0.
Part Three: Putting It All Together
Now we just need to add the wind vectors to our petal ring. Since we started off using arrays, we can do this in one fell swoop, like so:
petalvecs = windvecs + startvecs plt.scatter(petalvecs[:,0],petalvecs[:,1]) plt.show()
This produces the following graph:

Finally, I messed around with the numbers (petal number, average wind strength, wind deviation, and inner/outer ring radii), made the graph a little bigger and more square, changed the marker color/size/type, and added a background for some finishing touches.
As promised, these are our Monte Carlo Petals:

Nice. They’re not quite as visually appealing as the real thing, but I think it has its own simple beauty.
There’s still a lot more we can play around with, too.
Here’s the graph imposed on top of the (darker) starting positions:

And here’s a graph of each wind vector from its starting position to the final petal location (I reduced the petal amount, since it’s not really interesting in the form of a jumbled mass of white and magenta):

What else? We could directly plot the density as the darkness of a color, and figure out a function for the expected density value based on the input parameters.
And we could also mess around more with the variables themselves—wind deviation, average wind, petal amount, and the inner/outer ring radii—to make other pretty graphs and figure out the patterns that emerge from changing those numbers. Needless to say, there’s a lot I left unexplored.
What do you think? Have at it, and tell me how it goes.





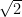 ), and so on. The sum would then be
), and so on. The sum would then be 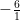 (the 6 nearest neighbors at distance 1) +
(the 6 nearest neighbors at distance 1) + 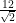 (there are 12 next-closest atoms distance
(there are 12 next-closest atoms distance  (the 8 “corners” of the first 3x3x3) +
(the 8 “corners” of the first 3x3x3) + 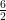 (similar to the nearest neighbors but one out) and so on.
(similar to the nearest neighbors but one out) and so on.

